

In der Software-Sicherheit verschiebt KI gerade den Engpass: Nicht mehr das Finden von Schwachstellen ist das Hauptproblem, sondern ihre Bewertung, Priorisierung und Behebung. Erst war es statische Analyse, dann LLM-gestütztes Code-Review, jetzt sind es Agenten, die Repositories selbständig durchpflügen, Exploits bauen und Patches vorschlagen. Jede dieser Stufen wird gern als nächste Generation verkauft, als ob man eine ältere Technik ablöst. Das stimmt nicht. Was tatsächlich passiert, ist eine Eskalationsleiter. Jede Stufe kauft mehr Fähigkeit und bringt einen neuen Versagensmodus mit. Die Risikoklasse wechselt mit, nicht nur die Toolauswahl.
Die drei Stufen lassen sich sauber trennen, an aktuellen Benchmarks messen und an ihren jeweiligen Bruchstellen prüfen. Die durchgehende Linie ist eine Kette aus drei Gliedern: Schwachstellen finden, Exploitability nachweisen, sauber fixen. An dieser Kette entscheidet sich, was KI in der Software-Sicherheit wirklich leistet. Wer nur Fundzahlen vergleicht, misst am falschen Glied.
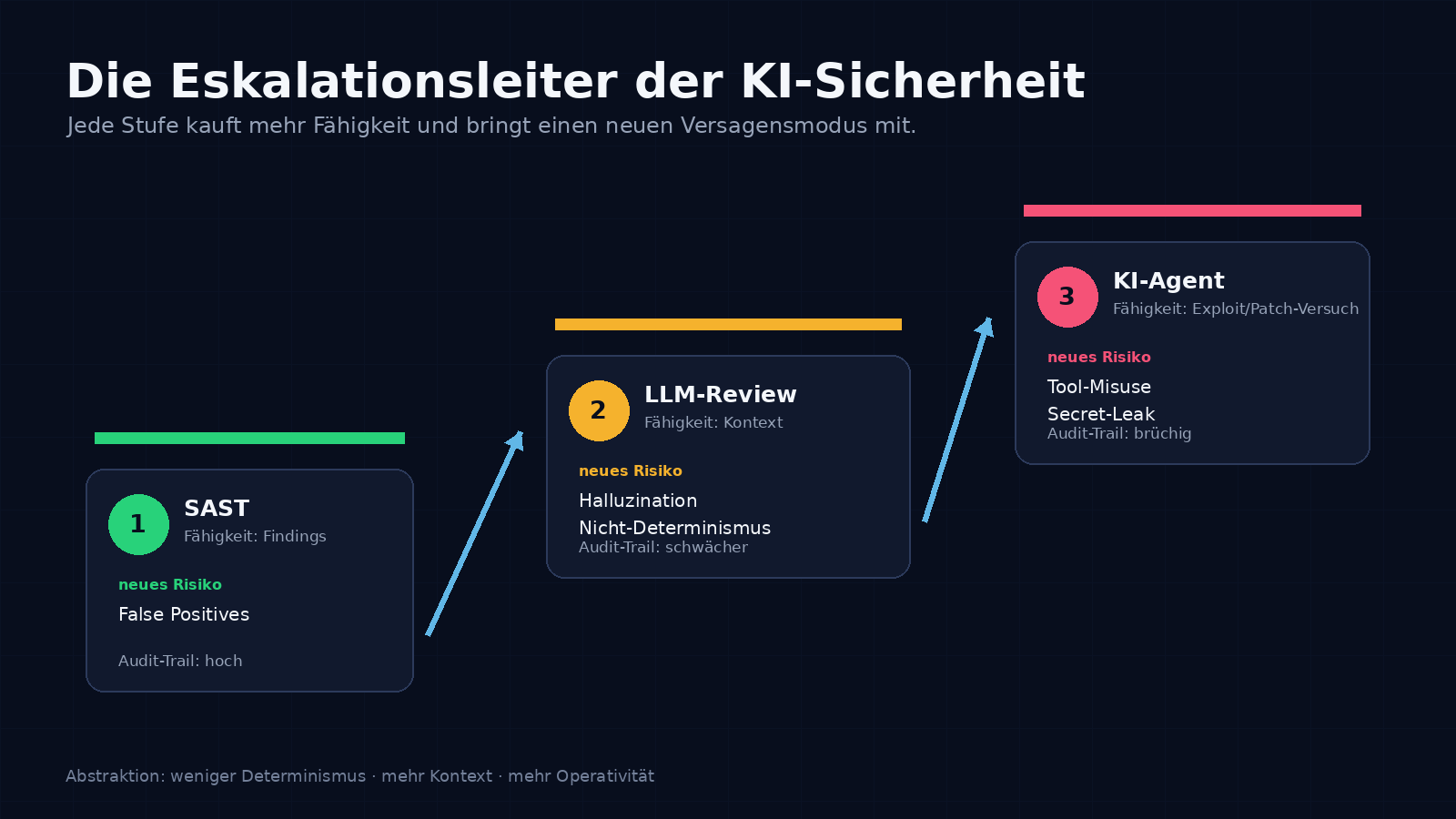
Stufe 1: Statische Analyse, der bekannte Schmerz
Klassische SAST-Tools, ob regelbasiert oder mit klassischen ML-Modellen, sind in jedem ernstzunehmenden Engineering-Workflow seit Jahren vertreten. Sie sind deterministisch, versionierbar und auditierbar. Wenn der Build-Server heute eine Warnung ausspuckt, kann morgen mit demselben Commit dieselbe Warnung reproduziert werden. Das ist der Punkt, an dem Compliance-Auditoren ein Häkchen setzen.
Der Preis ist bekannt: Recall hoch, Precision miserabel. Datenflussanalyse markiert jedes Pattern, das einer Vulnerability ähnelt, ohne zu verstehen, ob der Pfad in Produktion erreichbar ist, ob Eingaben gefiltert werden, ob die Funktion überhaupt aufgerufen wird. Teams verbringen einen erheblichen Teil ihrer AppSec-Stunden damit, False Positives aus Reports zu entfernen. Das ist nicht romantisch, aber es ist nachvollziehbar. Das Verhalten ist bekannt und reproduzierbar.
Die wichtigste Eigenschaft von Stufe 1 ist Berechenbarkeit. Der Auditierer kann nachvollziehen, warum eine Warnung kam, der Entwickler kann sie dokumentieren, das Tool gibt morgen wieder dieselbe Antwort. Auf den nächsten Stufen wird genau diese Eigenschaft schwächer.
Stufe 2: LLM-Review, Kontext gegen Audit-Trail
Sobald ein LLM Code-Reviews macht, ändert sich die Art der Findings grundsätzlich. Das Modell versteht Funktionsnamen, Kommentare, Aufruf-Kontext. Es erkennt Logikfehler, die kein regelbasierter Scanner je sehen wird: vertauschte Argumente in einer Authorization-Funktion, eine fehlerhafte State-Machine in einem Payment-Flow, ein Race zwischen Check und Use, das nur sichtbar wird, wenn man die Datei in ihrer Geschäftslogik liest. Das ist ein echter Sprung in der Qualität der Treffer.
Der Preis dafür ist drei Dinge gleichzeitig: halluzinierte Findings, Nicht-Determinismus, schwacher Audit-Trail. Das Modell schreibt Issues, die plausibel klingen, aber im Code so nicht stehen. Es referenziert Funktionen, die es leicht falsch benennt. Es widerspricht sich beim zweiten Lauf. Bessere Treffer und schlechtere Nachvollziehbarkeit kommen im selben Paket.
Die Forschung zu PentestGPT V2 zeigt das Muster aus einer Pentest-Perspektive. Die Autoren analysierten 28 LLM-basierte Pentest-Systeme und unterschieden zwei Fehlerklassen: technisch behebbare Type-A-Fehler wie fehlende Tools, schwache Prompts und Wissenslücken, sowie hartnäckige Type-B-Fehler bei Planung, Zustandsmanagement und Einschätzung der Aufgabenschwierigkeit. Als Warnsignal für Code-Review-Systeme ist das relevant, aber nicht eins zu eins übertragbar: Sobald ein LLM-basiertes System selbst entscheiden muss, welcher Pfad relevant ist, werden dieselben Fehlerklassen plausibel. Bewiesen ist damit kein Code-Review-Befund, aber die Risikolinse ist nützlich.
Ein zweiter Befund aus derselben Arbeit betrifft Kontextlast. Im Pentest-Kontext bleibt die Genauigkeit bis etwa 40 Prozent Context Load stabil bei rund 94 Prozent. Bei 60 Prozent fällt sie auf 78 Prozent, bei 80 Prozent auf 61 Prozent. Das gilt primär für agentengesteuerte Pentest-Systeme. Für LLM-Code-Review ist es kein Beweis, aber ein praktisches Warnsignal: Grosse Module im Kontext erhöhen das Risiko, dass relevante Inhalte verschwinden oder falsch gewichtet werden.
Der Audit-Trail wird ab dieser Stufe deutlich schwächer. SAST kann ich auf dem Build-Server zurücklaufen lassen und bekomme bit-identische Ergebnisse. Ein LLM-Review hat keinen reproduzierbaren Pfad zwischen Input und Finding. Wer Modellversion einfriert, Temperatur senkt und Prompts versioniert, bekommt trotzdem keine Determinismus-Garantie der Vorgängerstufe zurück. Für gewisse Compliance-Regime ist das ein Problem, das man heute oft unter den Teppich kehrt.
Stufe 3: KI-Agenten mit Repo-Zugriff, die mächtigste und unsicherste Stufe
Stufe 3 sind Agenten, die selbständig im Repository operieren. Sie lesen Code, führen Tools aus, schreiben Exploits, reproduzieren Schwachstellen, manche schlagen Patches vor. Das ist die Liga, in der MAPTA, ZeroDayBench und das AIxCC-Ökosystem rund um OSS-CRS spielen, mit klar unterschiedlichem Fokus: MAPTA führt aktive Exploits aus, um Exploitability nachzuweisen; ZeroDayBench ist ein Benchmark, der prüft, ob Agenten valide Patches schreiben, die gegen vorhandene Live-Exploits standhalten.
Was die Benchmarks tatsächlich messen
MAPTA ist ein Multi-Agent-System für Web-Application-Security-Assessments. Auf dem XBOW-Benchmark mit 104 Challenges erreicht es laut Autoren 76,9 Prozent Gesamterfolg; die durchschnittlichen LLM- und API-Kosten liegen dort bei 0,073 Dollar pro erfolgreicher Challenge im Median und 0,357 Dollar pro Fehlschlag. Auf einer anderen Skala arbeitet der Real-World-Test: In zehn Open-Source-Projekten mit 8K bis 70K GitHub-Stars findet das System 19 Schwachstellen, davon 14 high oder critical, zehn unter CVE-Review. Die durchschnittlichen LLM- und API-Kosten pro vollständigem Real-World-Assessment lagen bei 3,67 Dollar. Das sind konkrete Zahlen, die zeigen, dass autonome Agenten in einer engen Domäne sehr produktiv sein können, wenn sie mit Validierung gekoppelt sind.
Bemerkenswert an MAPTA ist die Differenzierung. SSRF liefert nahezu perfekte Performance, SSTI 85 Prozent, SQL Injection 83 Prozent, Command Injection 75 Prozent, XSS 57 Prozent. Blind SQL Injection landet bei 0 Prozent. Das Modell tut sich genau dort schwer, wo Feedback verzögert oder gar nicht sichtbar ist. Das ähnelt dem Mechanismus, den PentestGPT V2 als Zustandsmanagement-Problem identifiziert. Agenten sind so gut wie das Signal, das sie sehen.
Für Open-Source-Codebasen liefert ZeroDayBench ein wichtiges Gegenstück. Der Benchmark überträgt 22 portierte Schwachstellen mit CVSS ab 7,0 in funktional ähnliche Repositories, um Training-Data-Contamination zu reduzieren, und testet Frontier-Modelle in fünf Informationsstufen. ZeroDayBench misst Patch-Qualität: Ein Patch zählt nur, wenn er gegen einen vorhandenen Live-Exploit standhält. Die zentrale Aussage bleibt nüchtern: Frontier-LLMs lösen diese Aufgaben heute nicht autonom zuverlässig.
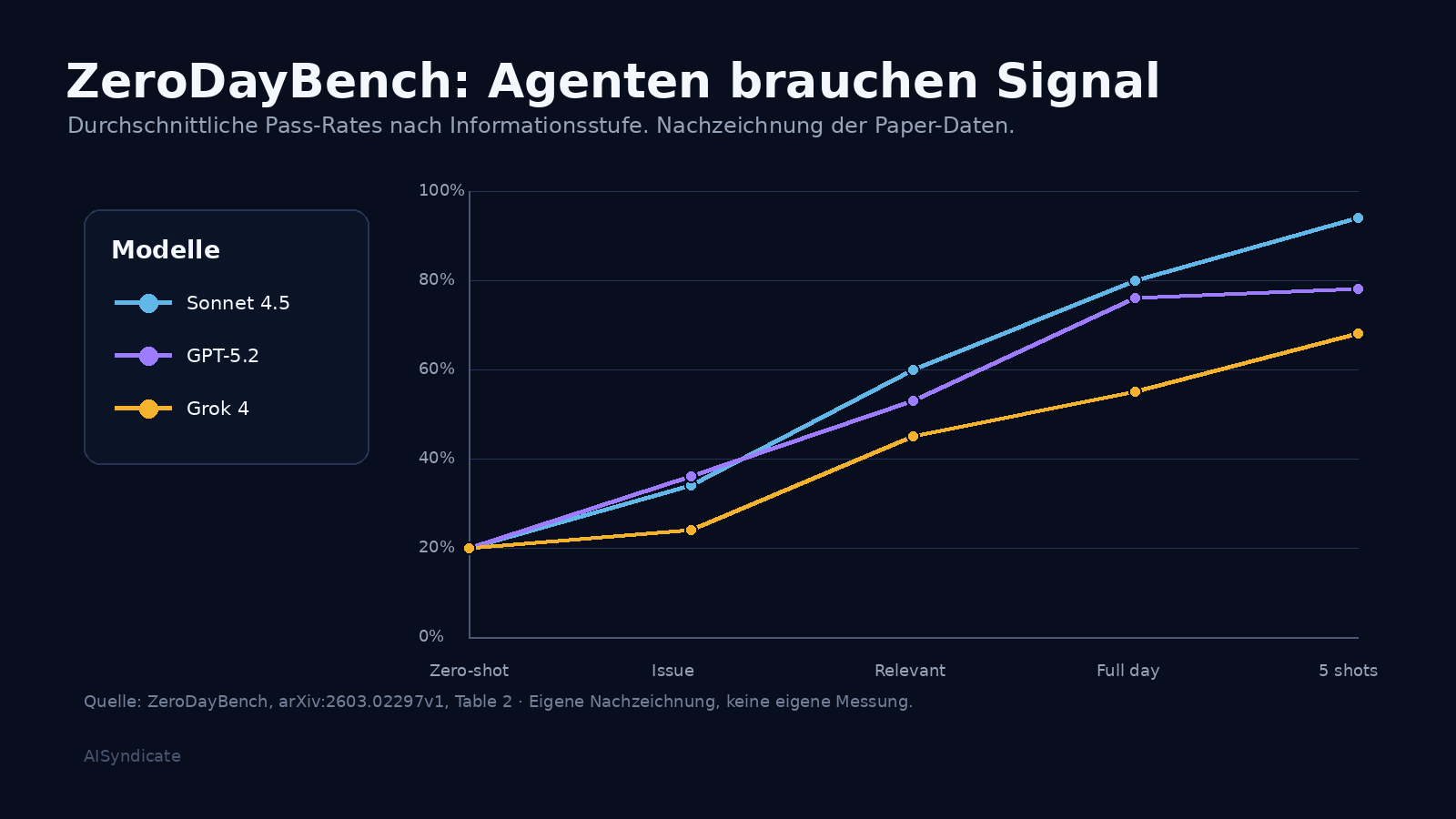
Die Diskrepanz zwischen MAPTA und ZeroDayBench ist kein Widerspruch. MAPTA arbeitet auf Web-Apps mit klaren HTTP-Signaturen und unmittelbarem Feedback, ZeroDayBench testet harte Logik- und Memory-Fehler in echten Codebasen mit reduziertem Contamination-Bias. Das Bild, das sich daraus zusammensetzt, ist konsistent: Wo ein Agent ein klares Signal hat, ob ein Exploit funktioniert, leistet er heute schon erstaunlich viel. Wo das Signal indirekt ist, verliert er die Spur.
OSS-CRS, AIxCC und die Realität von Cyber Reasoning Systems
Das AIxCC-Programm der DARPA hat von 2023 bis 2025 sieben Finalistenteams produziert. Alle sieben Systeme wurden open-gesourct, sind ausserhalb ihrer Ursprungsteams aber praktisch unbrauchbar. Das ist eine der ehrlichsten Aussagen im OSS-CRS-Paper. ATLANTIS, das erstplatzierte System, benötigt über 20 Azure Virtual Machines. Im Wettbewerb stellte AIxCC pro Team 50.000 Dollar an LLM-Credits bereit. Für den lokaleren OSS-CRS-Lauf setzen die Autoren dagegen ein Budget von 50 Dollar pro Kampagne auf einer Maschine an. Die Kostenfrage bleibt damit real, aber sie liegt nicht in einer einfachen Stundenzahl.
OSS-CRS soll diese Deployment-Lücke schliessen: lokal lauffähig, weniger Cloud-Lock-in, modularere Komponenten. Eine Portierung von ATLANTIS auf OSS-Fuzz fand zehn bisher unbekannte Bugs in acht Projekten, davon drei mit hoher Severity. Das ist ein belastbares Signal, dass Cyber Reasoning Systems jenseits des Wettbewerbsrahmens etwas leisten können. Es zeigt aber auch die Eintrittsschwelle: Engineering-Mannschaft, Budgetkontrolle, Sandboxing, Tool-Orchestrierung, Validierung.
Der ökonomische Nebeneffekt ist Stand Ende Mai 2026 branchenweit messbar. Das curl-Projekt hat sein Bug-Bounty-Programm Ende Januar eingestellt, nachdem AI-generierte, unbestätigte Reports die Reviewer überlasteten. FFmpeg-Maintainer bezeichneten patchlose Findings von Googles KI-Tool öffentlich als «CVE Slop».
Das Bild blieb aber nicht bei «KI-Reports sind Müll»: Daniel Stenberg berichtete im April, der reine Slop sei bei curl zurückgegangen, während Volumen und Qualität stiegen und fast alle Reports KI nutzen. Genau das verschärft die These. HackerOne meldet 76 Prozent mehr Einreichungen bei weiter rund 25 Prozent echten Lücken; HackerOne pausierte das Internet Bug Bounty, GitHub verschärfte seine Bounty-Regeln, Nextcloud stoppte finanzielle Prämien. Die Bounty-Ökonomie kippt, weil Findung schneller skaliert als Triage und Fixes.
Was Stufe 3 zur Angriffsfläche macht
Der entscheidende Punkt in vielen Pitches fehlt: Stufe 3 ist selbst Angriffsfläche. Ein Agent mit Repo-Zugriff sieht typischerweise Secrets, Tokens, Tool-Outputs oder Produktions-Identifier. Er ruft externe Tools auf, lädt Dependencies, kommuniziert mit MCP-Servern. Jede Schnittstelle ist eine potenzielle Quelle für Prompt Injection, Tool-Misuse oder Datenleck.
Die MCP-Studie der University of Delaware (DSN 2026) fand in 67.057 MCP-Servern 833 mit exploitierbaren Code-Schwachstellen und 18 mit verdächtigen Tool-Beschreibungen. Für produktive Security-Agenten heisst das: Die Werkzeuge, die der Agent benutzt, sind ein Supply-Chain-Vektor. Die Infrastrukturfrage habe ich in der AISyndicate-Analyse zum MCP-Standardkampf um die KI-Agenten-Infrastruktur ausführlicher behandelt.
Prompt Injection im Repo selbst ist die zweite Variante. Ein Angreifer, der einen PR einreicht oder Kommentare in Code platziert, kann den Agenten zu anderen Schritten drängen als beabsichtigt. Das ist die direkte Folge aus fremdem Input plus Tool-Zugriff. Warum Guardrails dafür kein Schutzwall sind, steht ausführlicher in der AISyndicate-Analyse zu fragilen LLM-Guardrails.
Die vier Dimensionen, sauber über die Stufen gelegt
Wenn man die Stufen an vier Dimensionen vergleicht, wird das Trade-off-Muster sichtbar.
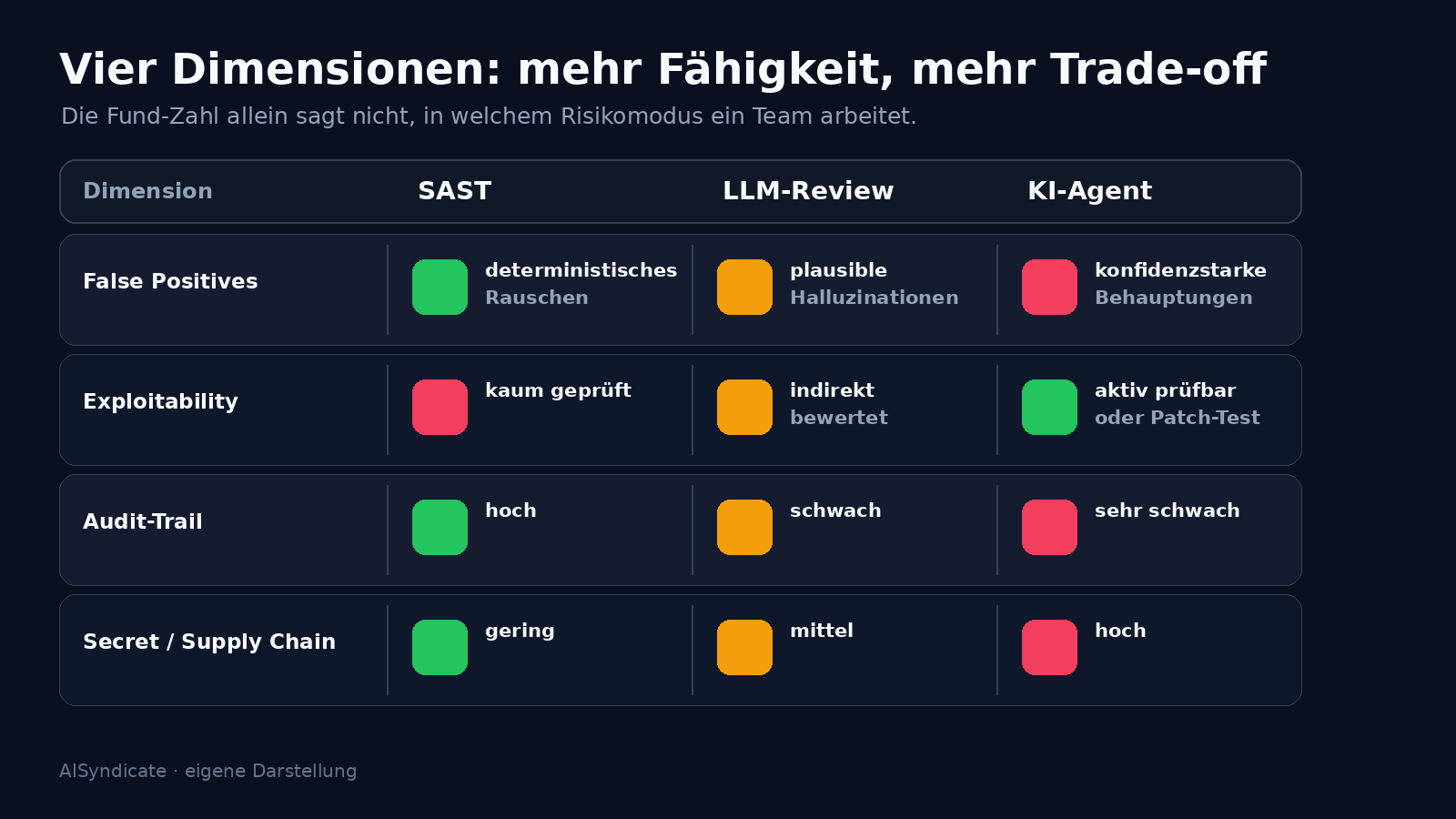
False Positives verschwinden nicht, sie wechseln den Modus. Stufe 1 produziert deterministisches Rauschen, Stufe 2 plausible Halluzinationen, Stufe 3 konfidenzstarke Behauptungen mit teilweise validierten, teilweise erfundenen Exploit-Schritten.
Exploitability wird erst auf Stufe 3 ernsthaft adressiert. MAPTA prüft aktive Ausnutzbarkeit, ZeroDayBench prüft Patch-Qualität gegen Live-Exploits. Beides ist wertvoll, aber nicht dasselbe.
Audit-Trail wird ab Stufe 2 schwächer. Tool-Calls lassen sich loggen, Outputs versionieren, doch ein reproduzierbarer Pfad von Input zu Finding ist nicht mehr möglich. Für regulierte Branchen ist das die schwierigste Eigenschaft der neuen Generation.
Secret-Leaks und Supply-Chain entstehen erst mit Stufe 3. Ein Agent, der Tools ausführt und Repos liest, kann durch Prompt Injection oder kompromittierte Tool-Server zum Datenleck werden.
Signal der Woche abonnieren
Eine Analyse pro Woche. Kein Feed, kein Alarmismus.
Kostenlos als Member. Gratis abonnieren
Antipatterns & Systemische Risiken
In Diskussionen mit Security-Teams und in Vendor-Pitches tauchen dieselben Fehlmuster immer wieder auf.
Fund-Zahlen als Erfolgsmetrik. Ein Stufe-3-Agent kann pro Tag dreistellige Findings produzieren. Wenn die Triage-Kapazität nicht mitwächst, vergrössert sich der Backlog, ohne dass das Risiko sinkt. Wer Mehrwert behauptet, muss Time-to-Patch zeigen, nicht Time-to-Finding.
Agenten ohne Sandbox. Ein Agent, der Tools ausführt und Repos liest, gehört in eine isolierte Umgebung mit beschränktem Egress, ohne Production-Credentials im Kontext, mit klaren Limits für Tool-Calls und Token-Budget. Wer einem Agenten einen Personal-Access-Token mit Schreibrechten gibt und ihn fremde Pull-Requests reviewen lässt, hat das Threat Model nicht verstanden. Dazu passen zwei frühere AISyndicate-Analysen: LangSmith-Sandboxes für KI-Agenten und NVIDIA NemoClaw. Beide behandeln Sandboxing als Infrastrukturproblem, nicht als Promptproblem.
LLM-Review als Ersatz für SAST. In mehreren Teams ist zu beobachten, dass nach Einführung eines LLM-Review-Tools die regelbasierte Pipeline rausgenommen wurde. Das ist falsch. Stufe 2 ergänzt Stufe 1, sie ersetzt sie nicht. Die deterministische Pipeline ist Compliance-Fundament, die LLM-Schicht ist Kontextverstärker. Beides muss laufen.
Benchmarks ohne Kontamination-Disziplin. ZeroDayBench ist nicht der erste Versuch, Contamination zu kontrollieren, aber einer der ehrlichsten. Vendor-Demos auf gepflegten CTF-Maschinen zeigen oft Memorization, nicht Fähigkeit. Im Sales-Pitch sind es 90 Prozent Erfolgsrate, im eigenen Stack 30. Der Fehler liegt im Benchmark-Setup, nicht zwingend beim Vendor.
Systemisch betrachtet sind drei Risikoklassen zentral. Erstens die Angreiferseite: Dieselben Agenten, die MAPTA für Verteidigung nutzt, lassen sich für offensive Aufklärung verwenden. Laut MAPTA-Studie lagen die durchschnittlichen LLM- und API-Kosten pro vollständigem Assessment im Experiment bei 3,67 Dollar. Angreifer können dieselbe Toolchain nutzen, ohne auf Audit-Trail oder sauberen Patch zu achten. Die breitere Angriffsperspektive habe ich in der AISyndicate-Analyse zu KI in Malware beschrieben.
Zweitens Agenten als Insider-Risiko. Die Survey zu Sicherheitsbedrohungen LLM-basierter Agenten markiert offene Lücken, die keine Vendor-Demo schliesst. Wer einen Agenten mit Repo-Schreibrechten betreibt, sollte das wie Mitarbeiter-Onboarding behandeln: Least Privilege, Logging, Off-Boarding.
Drittens Governance. Sandboxing, Egress-Filter, Tool-Whitelists und Prompt-Injection-Tests sind Eintrittsbedingung für Stufe 3. Ohne diese Bausteine entsteht kein belastbares Security-Engineering.
Zwei Second-Order-Effekte für die nächsten 12 bis 24 Monate
Zwei mittelfristige Effekte halte ich für wahrscheinlicher, als sie heute diskutiert werden.
Erstens, die Triage-Krise wird zur Tarifbremse für Bug-Bounty-Programme. curl und FFmpeg waren die frühen Warnsignale; inzwischen ist das Muster breiter. HackerOne, GitHub und Nextcloud zeigen unterschiedliche Varianten derselben Reaktion: weniger offene Annahme, höhere Qualitätsbarrieren, weniger oder keine pauschalen Prämien. Programme werden Reproduktion in einer definierten Sandbox verlangen oder das Modell auf Validierungspflicht durch den Reporter umstellen. Mittelgrosse Open-Source-Projekte ohne Sponsoring werden Bounty-Programme reduzieren oder schliessen.
Zweitens, Sandboxing und Egress-Kontrolle werden Eintrittsbedingung für Security-Versicherungen. Cyber-Versicherer verlangen heute schon MFA, EDR und Backups als Mindestkriterien. Sobald Schäden durch missbrauchte Security-Agenten dokumentiert sind, werden Egress-Filter und Sandboxing-Standards in die Fragebögen wandern. Sandboxing wird dann Voraussetzung für Betriebsfähigkeit.
Was an der Kette wirklich entscheidet
Die Kette aus Finden, Exploitability nachweisen, sauber fixen ist das, was zählt. Stufe 1 liefert nur das erste Glied und liefert es schlecht. Stufe 2 liefert ein besseres erstes Glied, aber kein zweites. Stufe 3 erreicht das zweite Glied, scheitert aber am dritten: dem sauberen Patch im Produktionscode.
ZeroDayBench zeigt diese Grenze hart. Ein Patch zählt nur, wenn ein Live-Exploit danach blockiert wird. Heutige Frontier-Modelle liefern das nicht autonom zuverlässig. Die Industrie spricht über autonome Cyber-Defense und liefert tatsächlich automatisierte Findings ohne automatisiertes Fixing. Das ist ein Fortschritt, aber er löst nicht das eigentliche Problem.
Die Engpassressource bleibt menschliches Urteil über Exploitability und Patch-Qualität. Genau die skaliert nicht mit der Anzahl der Findings. Erfolgreiche Stufe-2- und Stufe-3-Setups ersetzen dieses Urteil nicht. Sie verlagern es: weniger Review von Findings, mehr Review von Patch-Qualität und Exploit-Validierung. Das ist eine Umorganisation, keine Tool-Frage.
Die meisten Security-Teams, mit denen ich rede, kaufen gerade Stufe 3, ohne Stufe 2 sauber zu betreiben und ohne Stufe 1 zu pflegen. Das ist Mode, nicht Engineering. Ich würde heute keinen Stufe-3-Agenten ohne strikten Network-Egress, Tool-Whitelist und klares Triage-Konzept betreiben, und ich würde keinem Vendor glauben, der diese Bausteine nicht standardmässig anbietet.
Praxisimplikation für AppSec-Teams
Drei konkrete Schlüsse aus den Befunden.
Erstens: Die drei Stufen sind als Schichtung zu behandeln, nicht als Generationen. SAST bleibt aktiv, LLM-Review ergänzt auf kritischen Pfaden, Stufe-3-Agenten kommen in dedizierte, isolierte Umgebungen für hochwertige Targets. Wer alle drei Schichten betreibt, hat den besten Kompromiss aus Determinismus, Kontextverständnis und Exploitability-Nachweis.
Zweitens zählt Time-to-Patch, nicht Time-to-Finding. Stufe-3-Agenten erhöhen den Input für die Triage-Pipeline um Grössenordnungen. Wenn die Pipeline nicht mitwächst, entsteht Sicherheits-Theater. Eine ehrliche Metrik ist die Zeit zwischen Finding und produktivem Patch, gewichtet nach Severity.
Drittens braucht Stufe-3-Deployment eine eigene Threat-Model-Runde. Was sieht der Agent im Kontext, welche Tools darf er nutzen, welche Egress-Ziele sind erlaubt, was passiert bei Prompt Injection im PR. Diese Fragen gehören vor den Pilot, nicht in den ersten Incident.
Das Bild bleibt nüchtern. KI in der Software-Sicherheit ist nicht der Hype aus Vendor-Pitches und nicht der Bluff aus Skeptiker-Threads. Sie verschiebt Findung und Validierung, ohne dass Triage und Patch-Qualität automatisch mitskalieren. Wer das organisiert, gewinnt. Wer auf Fund-Zahlen optimiert, baut sich einen Backlog, der ihn überrollt.
Was ist der Unterschied zwischen SAST, LLM-Review und KI-Agenten?
SAST findet bekannte Muster deterministisch. LLM-Review ergänzt Kontext und Logikverständnis, ist aber weniger reproduzierbar. KI-Agenten gehen weiter: Sie nutzen Tools, prüfen Exploitability und können Patches versuchen.
Warum sind mehr gefundene Schwachstellen nicht automatisch mehr Sicherheit?
Weil jede Meldung bewertet, priorisiert und behoben werden muss. Wenn Triage und Patch-Kapazität nicht mitskalieren, wächst der Backlog schneller als die tatsächliche Risikoreduktion.
Was misst ZeroDayBench eigentlich?
ZeroDayBench prüft, ob Modell-Patches echte Exploits stoppen. Gemessen wird damit Finding-Qualität plus die Frage, ob ein Fix gegen eine konkrete Schwachstelle hält.
- →ZeroDayBench: Benchmark für LLM-Agenten auf neuartigen kritischen Schwachstellen (arXiv 2603.02297)
- →PentestGPT V2: Tool-and-Skill-Layer, Difficulty Assessment, Attack Tree Search (arXiv 2602.17622)
- →MAPTA: Multi-Agent-System für autonome Web-Application-Security-Assessments (arXiv 2508.20816)
- →OSS-CRS: Lokal deploybares Framework für Cyber Reasoning Systems (arXiv 2603.08566)
- →MCP-Ökosystem-Sicherheitsstudie (arXiv 2510.16558)
- →Survey: Sicherheitsbedrohungen LLM-basierter Agenten (arXiv 2406.02630)
- →The end of the curl bug-bounty (daniel.haxx.se, Januar 2026)
- →FFmpeg Calls Google's AI Bug Reports «CVE Slop» (It's FOSS)
- →High-Quality Chaos: curl-Update zu KI-Reports (daniel.haxx.se, April 2026)
- →HackerOne 2026 Security Report: Report-Volumen und Validierungsquote
- →GitHub verschärft Bug-Bounty-Auszahlungen (The New Stack)
- →Nextcloud stoppt Bug-Bounty-Prämien wegen Low-Quality-Reports (Techzine)


