

AGI 2027: Die falsche Frage an die richtigen Daten
AGI 2027 ist nicht deshalb eine schlechte These, weil die Daten langsam wären. Die Daten sind brutal schnell. Die Schwäche liegt im Etikett. METR misst wachsende Time Horizons bei agentischer Computerarbeit. ARC-AGI-3, Odysseys und neuere Benchmark-Papers zeigen gleichzeitig, dass allgemeine, adaptive, effiziente Intelligenz etwas anderes ist. Die präzisere Frage lautet: Welche Fähigkeit, in welcher Umgebung, mit welcher Zuverlässigkeit?
Die Debatte über AGI 2027 hat sich gedreht. Vor einem Jahr konnte man noch relativ bequem sagen: Die Benchmarks sind zu dünn, die Extrapolation zu grob, die Modelle zu spröde. Diese bequeme Position ist weg. Die aktuellen Daten zu agentischen Systemen sind stark genug, dass reine Fortschrittsskepsis unseriös wäre.
Die eigentliche Frage liegt deshalb woanders: AGI 2027 ist eine zu grobe Formel für eine Forschungslage, die inzwischen viel präziser geworden ist.
METR misst etwas Reales. Computer-Use-Agenten werden schneller, robuster und länger handlungsfähig. Gleichzeitig zeigen andere aktuelle arXiv-Arbeiten, dass diese Fähigkeit sich nicht automatisch in allgemeine, effiziente, adaptive Intelligenz übersetzt. Der Fehler liegt nicht in den Daten. Der Fehler liegt im Etikett.
I. METR ist stark, aber eng
Das METR-Paper „Measuring AI Ability to Complete Long Software Tasks“ hat die Debatte aus gutem Grund geprägt. Es schlägt eine Messgrösse vor, die intuitiv verständlich ist: die 50%-Time-Horizon. Gemeint ist die Länge einer Aufgabe, gemessen in menschlicher Bearbeitungszeit, die ein KI-Agent mit 50% Erfolgswahrscheinlichkeit schafft.
Das ist besser als viele klassische Benchmarks. Ein Prozentwert auf einem Multiple-Choice-Test sagt wenig darüber aus, ob ein System eine echte Aufgabe über Stunden stabil verfolgt. Eine Time-Horizon sagt mehr: Wie lang darf ein Projekt werden, bevor das Modell den Faden verliert?
Die Antwort verschiebt sich schnell. In METRs aktuellem TH1.1-Live-Datensatz stehen 25 veröffentlichte Modellmessungen, davon 22 auf TH1.1; 17 sind als State-of-the-Art markiert. Claude Opus 4.6 wird dort mit einer 50%-Time-Horizon von rund 719 Minuten geschätzt, Gemini 3.1 Pro mit rund 384 Minuten, GPT-5.2 mit rund 352 Minuten und GPT-5.4 mit rund 342 Minuten. Die Konfidenzintervalle bleiben breit, aber die Richtung ist klar: Agentische Computerarbeit skaliert schnell.
Auch die Trendzahlen sind nicht gemütlich. Der über die gesamte Zeitreihe zusammengeführte METR-Trend liegt bei rund 188 Tagen Verdopplungszeit; ab 2023 liegt der Punktschätzer bei rund 129 Tagen. Wer daraus nur „Benchmark-Hype“ macht, liest die Daten nicht. Software-Agenten werden wirklich besser.
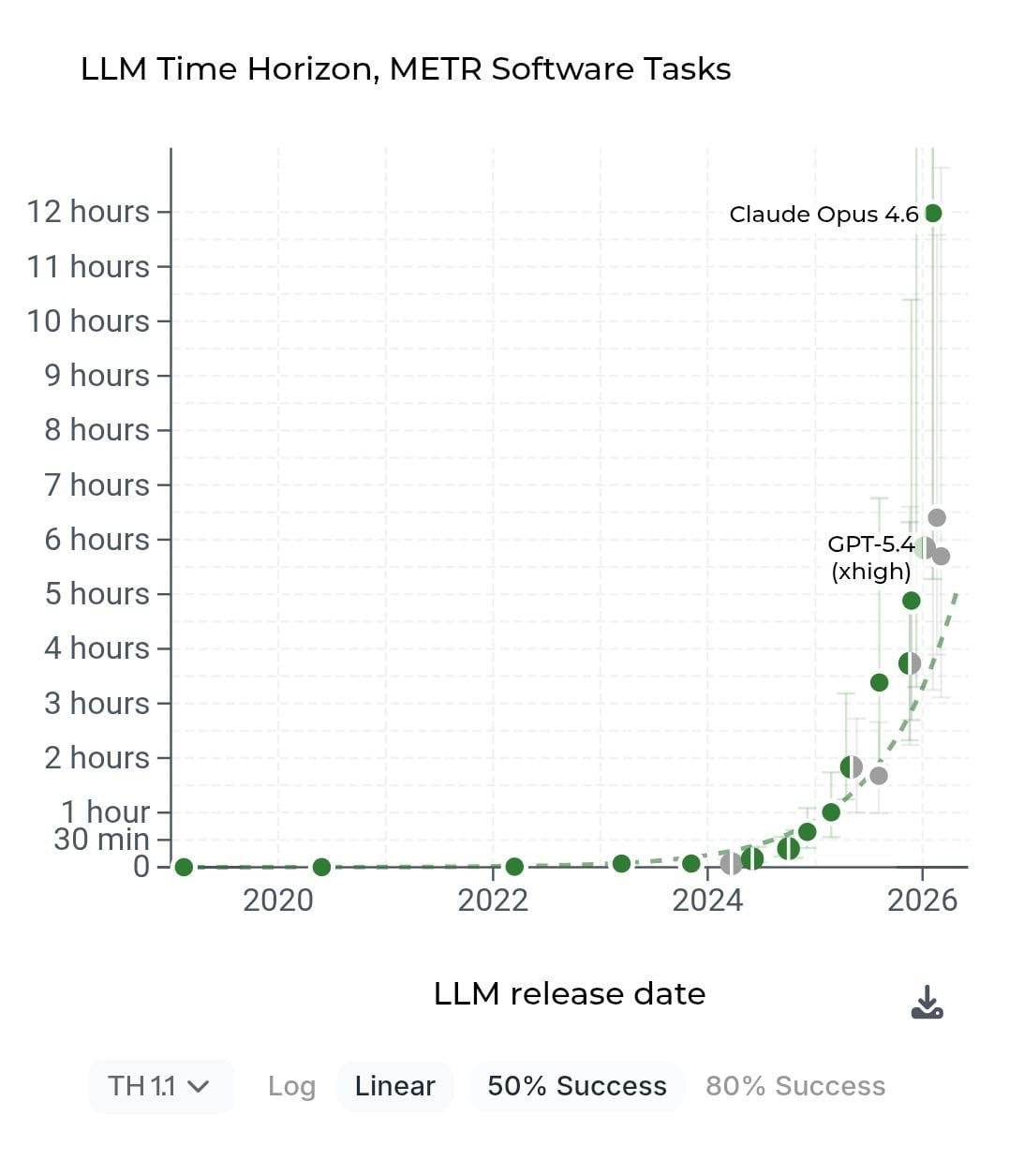
Der wichtigste neue Punkt liegt im Umschalten von 50% auf 80% Erfolg. Im Dashboard liegt Claude Opus 4.6 bei rund 719 Minuten 50%-Time-Horizon, aber nur bei rund 70 Minuten 80%-Time-Horizon. Das ist kein Detail. Es ist die Differenz zwischen „funktioniert in der Hälfte der Fälle“ und „ist zuverlässig genug, um Arbeit wirklich abzugeben“.
Auch METRs TH1.1-Update selbst stützt diese Lesart. Die neue Suite wächst von 170 auf 228 Tasks, lange Aufgaben ab acht Stunden steigen von 14 auf 31. Gleichzeitig hält METR fest, dass der Trend stark von der Task-Zusammensetzung abhängt und dass nur ein Teil der langen Tasks echte Human-Baseline-Zeiten hat. Anders gesagt: Je besser die Messung wird, desto sichtbarer wird, dass sie eine bestimmte Aufgabenverteilung misst, nicht „AGI“ als Gesamtphänomen.
Damit liefert METR ausgerechnet die beste Warnung vor der falschen Schlussfolgerung: Der Trend ist real, aber sein Geltungsbereich ist begrenzt. Wer daraus eine pauschale AGI-2027-These macht, überspringt genau die methodische Vorsicht, die METR selbst dokumentiert.
Aber hier beginnt die eigentliche Präzisionsarbeit. METR misst agentische Aufgaben in einer bestimmten Aufgabenverteilung: Software Engineering, Machine Learning, Cybersecurity und verwandte computerbasierte Arbeit. Das ist nicht eng im trivialen Sinn. Es ist relevant, anspruchsvoll und ökonomisch wichtig. Aber es ist nicht deckungsgleich mit allgemeiner Intelligenz.
Ein System, das zehn Stunden an einem Softwareproblem arbeiten kann, ist nicht automatisch ein System, das unbekannte Ziele in einer neuen Umgebung effizient erschliesst, langfristig lernt, soziale Ambiguität modelliert, multimodale Weltzustände versteht und über Monate konsistent handelt. Genau diese Unterscheidung verschluckt die Formel „AGI 2027“.
II. AGI ist kein einzelner Horizon-Wert
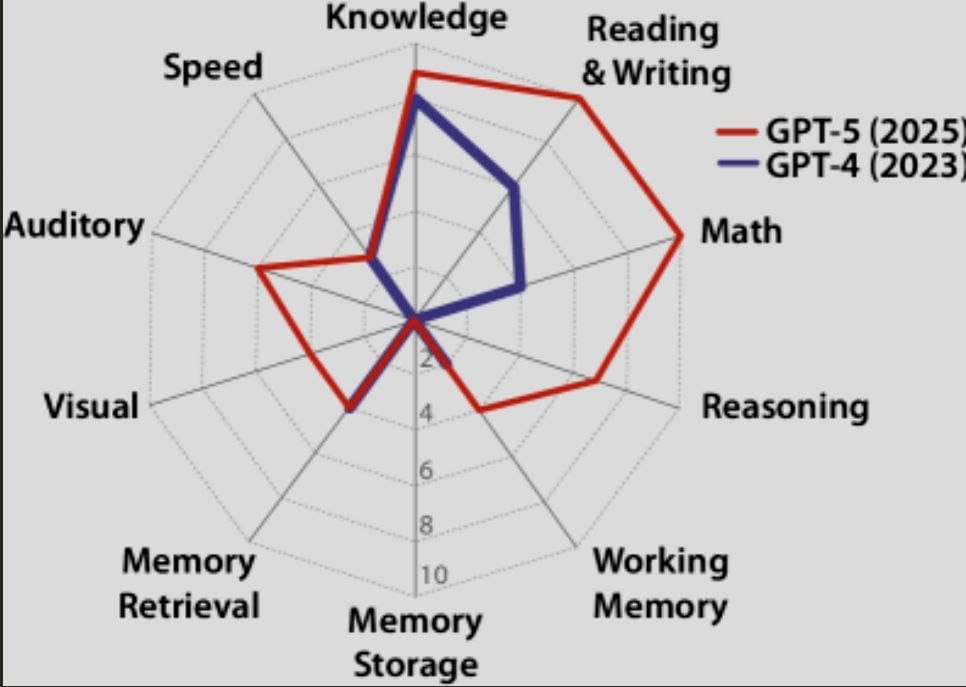
Das vielleicht beste Gegenmittel gegen die Timeline-Rhetorik ist eine Definition. Hendrycks, Song, Szegedy und zahlreiche weitere Autoren schlagen in „A Definition of AGI“ eine Operationalisierung vor, die allgemeine Intelligenz in zehn Fähigkeitsbereiche zerlegt: Wissen, Lesen und Schreiben, Mathematik, On-the-Spot-Reasoning, Working Memory, Langzeitgedächtnis-Speicherung, Langzeitgedächtnis-Abruf, visuelle Verarbeitung, auditive Verarbeitung und Geschwindigkeit.
Man muss diese konkrete Definition nicht als endgültig akzeptieren. Aber sie leistet etwas Wichtiges: Sie macht sichtbar, dass AGI ein Fähigkeitsprofil ist, kein einzelner Score. Ein Modell kann bei Wissen und mathematischen Aufgaben stark sein und gleichzeitig bei Langzeitgedächtnis, visueller Generalisierung oder adaptivem Verhalten schwach bleiben.
Das Paper quantifiziert diese Ungleichmässigkeit (Jaggedness) explizit. GPT-4 kommt in ihrem Schema auf 27%, GPT-5 auf 58%. Das ist enormer Fortschritt. Aber es ist auch ein klares Signal: Zwischen „sehr leistungsfähiges KI-System“ und „AGI im Sinn menschlich breiter kognitiver Vielseitigkeit“ liegt noch eine strukturierte Lücke.
Diese Lücke ist der Grund, warum „AGI 2027“ als Satz so verführerisch und so unsauber ist. Er ersetzt ein mehrdimensionales Messproblem durch ein Datum. Aus Fähigkeitsprofilen wird ein Countdown. Aus Unsicherheit wird Dramaturgie.
III. ARC-AGI-3 zeigt die andere Seite der Agentenfähigkeit
ARC-AGI-3 ist deshalb so interessant, weil es die Frage anders stellt als METR: Kann ein System in neuen, abstrakten, turn-basierten Umgebungen Ziele erschliessen, Dynamiken modellieren und effiziente Aktionsfolgen planen, ohne explizite Instruktionen?
Der Unterschied ist entscheidend. ARC-AGI-3 vermeidet Sprache und externes Wissen bewusst. Es geht nicht darum, ob ein Modell genug Webtext gesehen hat oder ein bekanntes Tool bedienen kann. Es geht um fluid adaptive efficiency (flexible Anpassungsintelligenz): Wie effizient erwirbt ein System eine neue Fähigkeit beim ersten Kontakt mit einer unbekannten Umgebung?
Die Zahlen sind brutal. Laut Paper können Menschen 100% der ARC-AGI-3-Umgebungen lösen. Frontier-Systeme lagen im März 2026 unter 1%. Das ist kein Beweis, dass Modelle „nicht denken“. Aber es ist ein starkes Gegengewicht zur Gleichsetzung von Software-Agentenfortschritt mit allgemeiner Agentenintelligenz.
ARC-AGI-3 sagt: Ja, moderne Systeme können in verifizierbaren Domänen beeindruckend sein. Aber wenn Ziel, Spielregeln und Dynamik erst erschlossen werden müssen, bricht die Sache noch ganz anders auf. Genau dort beginnt der Unterschied zwischen „kann lange eine Aufgabe bearbeiten“ und „versteht eine neue Welt effizient“.
IV. Odysseys bringt die Debatte zurück ins offene Web
Odysseys setzt an einer anderen Stelle an. Es testet realistische, lange Web-Workflows: Produkte vergleichen, Reisen planen, Informationen über mehrere Websites hinweg zusammentragen, Kontext halten, Ergebnisse synthetisieren. Kurz: Aufgaben, die näher an tatsächlicher Computerarbeit im offenen Web liegen als viele Mini-Benchmarks.
Auch hier ist das Ergebnis nicht beruhigend langsam, aber deutlich weniger triumphal als die AGI-Erzählung. Odysseys umfasst 200 Long-Horizon-Webtasks, abgeleitet aus realen Browsing-Sessions und bewertet mit durchschnittlich 6,1 Rubric-Kriterien pro Aufgabe. Die stärksten getesteten Modelle erreichen 44,5% perfekte Task Success Rate. Das ist respektabel. Aber es ist nicht „allgemeine Autonomie“. Es ist weniger als die Hälfte.
Noch wichtiger ist die Effizienz. Odysseys führt eine Trajectory-Efficiency-Metrik ein: Rubric Score pro Schritt. Selbst Frontier-Agenten erreichen nur 1,15%. Mit anderen Worten: Sie können teilweise ans Ziel kommen, aber sie verschwenden massiv viele Schritte. Ein Agent, der irgendwann zufällig oder mühsam ans Ziel kriecht, ist nicht dasselbe wie ein effizient handelndes intelligentes System.
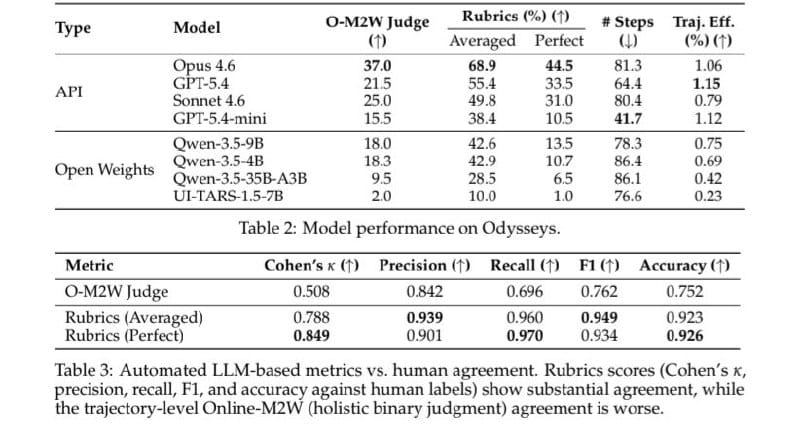
Damit fügen sich METR und Odysseys zu einem klaren Bild zusammen. METR zeigt: Software-nahe Agenten werden länger handlungsfähig. Odysseys zeigt: Sobald dieselbe Idee ins offene Web wandert, werden Erfolg, Effizienz, Kontextführung, Stop-Kriterien und Cross-Site-Reasoning zum Engpass. Das ist keine Widerlegung von METR. Es ist die notwendige zweite Achse.
Odysseys schliesst dabei auch die Lücke zwischen METR und ARC-AGI-3: Es ist realistischer als abstrakte Spielumgebungen, aber offener und schmutziger als viele sauber bewertbare Softwaretasks. Genau deshalb ist Odysseys analytisch wichtiger als eine weitere Hype-Quelle: Es zeigt, wo Agenten im Alltag scheitern, obwohl der Langhorizont-Trend real ist.
V. Selbst die Benchmarks sind noch nicht stabil genug
Dieser Punkt trifft auch METR direkt: Wir messen agentische Systeme noch nicht so sauber, wie viele Charts suggerieren. Das Paper „Establishing Best Practices for Building Rigorous Agentic Benchmarks“ analysiert genau dieses Problem.
Die Autoren zeigen, dass agentische Benchmarks leicht durch Task-Setup, Reward Design und Outcome-Verification verzerrt werden. Die Folgen sind nicht klein. Solche Fehler können Agentenleistung relativ um bis zu 100% über- oder unterschätzen. Bei CVE-Bench reduzierte die Anwendung ihrer Agentic Benchmark Checklist eine Performance-Überschätzung um 33%.
Die Beispiele sind fast komisch, wenn sie nicht so wichtig wären: SWE-bench Verified kann durch unzureichende Tests Patches akzeptieren, die ein Issue nicht wirklich lösen. In τ-bench konnte ein trivialer Agent mit leerer Antwort auf bestimmten unmöglichen Aufgaben als erfolgreich gelten. Das ist kein Randproblem. Das ist die Infrastruktur, auf der Capability-Narrative gebaut werden.
Daraus folgt nicht, dass alle Benchmarks wertlos sind. Im Gegenteil: Gute Benchmarks sind unverzichtbar. Aber je stärker eine These ist, desto stärker muss die Messkette sein. „AGI 2027“ ist eine sehr starke These. Dafür reicht kein einzelner Graph, kein einzelner Aufgabenmix und kein einzelner Erfolgswert.
Die eigentliche These
Die sauberste Position lautet deshalb: AGI 2027 ist die falsche Frage an die richtigen Daten.
Die richtigen Daten zeigen: Agenten werden bei verifizierbarer Computerarbeit schnell besser. Die falsche Frage macht daraus: Wann kommt AGI? Zwischen diesen beiden Sätzen liegt der ganze Unterschied.
Eine bessere Frage wäre: Welche Art von Aufgabe? In welcher Umgebung? Mit welchem Feedback? Mit welcher Erfolgswahrscheinlichkeit? Mit welcher Effizienz? Über welchen Zeithorizont? Mit welchem Gedächtnis? Mit welcher Fähigkeit, neue Ziele und Regeln zu erschliessen?
Wer so fragt, landet bei Fähigkeitsprofilen statt bei einem Datum. Software-Agenten können in manchen Bereichen früher transformativ werden, als viele Organisationen vorbereitet sind. Gleichzeitig können dieselben Systeme an fluid-adaptiver Effizienz, offenen Web-Workflows oder langfristigem Gedächtnis scheitern. Beides kann gleichzeitig wahr sein.
Systemische Risiken
Das erste Risiko ist begriffliche Überdehnung. Wenn jede bessere Time-Horizon-Messung als AGI-Signal gelesen wird, verschwinden die Unterschiede zwischen Software-Automation, Web-Agenten, adaptiver Problemlösung und allgemeiner Intelligenz. Dann wird aus einer nützlichen Messreihe ein politisches Schlagwort.
Das zweite Risiko ist falsches Deployment-Tempo. Organisationen können Software-Agenten zu spät ernst nehmen, weil sie auf das grosse AGI-Etikett warten. Sie können dieselben Systeme aber auch zu früh mit Produktivzugriffen ausstatten, weil ein einzelner Langhorizont-Wert beeindruckend aussieht. Beide Fehler haben dieselbe Ursache: Die Fähigkeit wird nicht als Profil beschrieben, sondern als Countdown.
Das dritte Risiko liegt in der Messkette. Benchmarks prägen Budgets, Regulierung und interne Roadmaps. Wenn Task-Design, Erfolgsprüfung oder Reward-Logik verzerrt sind, wandern diese Verzerrungen direkt in strategische Entscheidungen. Deshalb muss ein Benchmark zuerst offenlegen, welche Fähigkeit er unter welchen Bedingungen tatsächlich misst.
Signal der Woche abonnieren
Eine Analyse pro Woche. Kein Feed, kein Alarmismus.
Kostenlos als Member. Gratis abonnieren
VI. Was wir statt AGI-Timelines messen sollten
Wenn man die Forschungslage ernst nimmt, verschiebt sich der Fokus. Relevanter als das mythische Gesamtlabel ist die Teilfähigkeit: Was wird heute schon produktiv, morgen gefährlich überschätzt und übermorgen tatsächlich transformativ?
Für Software-Agenten sieht diese Matrix anders aus als für Web-Agenten, wieder anders als für abstrakte adaptive Umgebungen und nochmals anders als für Gedächtnis, Wahrnehmung oder soziale Modellierung. METR kann bei Software-Horizons recht haben, während ARC-AGI-3 bei fluid-adaptiver Effizienz ebenfalls recht hat. Odysseys kann zeigen, dass Web-Agenten Fortschritte machen, aber ineffizient bleiben. Das widerspricht sich nicht. Es beschreibt dieselbe Landschaft aus verschiedenen Höhen.
Diese Perspektive passt auch besser zu dem, was sich in anderen KI-Debatten zeigt: Der Stanford AI Index 2026 beschreibt schnellen, aber ungleich verteilten Fortschritt; die Debatte um fragile LLM-Guardrails zeigt, wie stark kontrollierte Tests und offene Umgebungen auseinanderfallen können. Genau dieses Muster taucht bei Agenten wieder auf: Benchmarks sind notwendig, aber sie sind keine Weltkarte.
Deshalb ist die brauchbare Einheit ein Capability-Profil: Aufgabe, Umgebung, Feedbackkanal, Fehlertoleranz, Kosten, Dauer, Gedächtnis, Tool-Zugriff und Prüfbarkeit. Erst wenn diese Parameter genannt werden, wird aus einer Prognose eine überprüfbare Aussage.
Der praktische Vorteil dieser Sprache ist nicht Vorsicht um der Vorsicht willen. Sie zwingt jede Behauptung, ihren Messpunkt offenzulegen. Wer sagt, Agenten würden 2027 „alles“ verändern, muss sagen, welche Klasse von Aufgaben gemeint ist und woran Scheitern erkannt wird.
Das ist journalistisch ehrlicher. Und es verhindert den merkwürdigen Reflex, jeden neuen Agentenwert entweder als Beweis für die nahe Superintelligenz oder als Hype abzutun. Die Realität ist unangenehmer: Einige Fähigkeiten werden sehr schnell praktisch relevant. Andere bleiben erstaunlich hartnäckig ungelöst. Wer beides gleichzeitig halten kann, versteht die Daten besser als die Timeline-Fraktion.
Fazit
Der AGI-2027-Satz lebt davon, dass er mehrere Ebenen zusammenzieht: Software-Horizon, Agentenfähigkeit, allgemeine Intelligenz, wirtschaftliche Automatisierung und Zukunftsdramaturgie. METR liefert starke Evidenz für eine dieser Ebenen. ARC-AGI-3, Odysseys, die Benchmark-Checklist und die AGI-Definitionsarbeit zeigen, warum die anderen Ebenen nicht einfach mitkommen.
Die Pointe ist nicht beruhigend. Sie ist präziser: Die nächsten zwei Jahre können für Software-Agenten extrem wichtig werden, ohne dass „AGI“ als Gesamtetikett bereits sauber erreicht ist. Wer nur auf das Wort wartet, verpasst die echten Verschiebungen. Wer das Wort zu früh ausruft, verwischt die Messung.
Die METR-Grafiken machen den Fortschritt sichtbar. Der 80%-Horizont macht die Grenze sichtbar. Beides gehört zusammen: Ohne den ersten Befund bliebe das Bild blind für Tempo, ohne den zweiten blind für Zuverlässigkeit.
AGI 2027 ist deshalb weniger eine Prognose als ein Stresstest für unsere Begriffe. Und im Moment bestehen die Daten den Test besser als das Label.
Widerlegt METR die Kritik an AGI 2027?
Nein. METR zeigt schnellen Fortschritt bei agentischen Software- und Computeraufgaben. Genau deshalb sollte man die Daten ernst nehmen. Aber METR belegt nicht automatisch allgemeine, domänenübergreifende AGI bis 2027.
Warum ist AGI 2027 die falsche Frage?
Weil AGI kein einzelner Benchmark-Wert ist. Neuere arXiv-Arbeiten zerlegen AGI in verschiedene Fähigkeiten: Reasoning, Gedächtnis, Wahrnehmung, adaptive Effizienz, Tool-Nutzung und Robustheit. Ein hoher Software-Horizon ersetzt dieses Profil nicht.
Welche neuen Quellen stützen diese Einordnung?
ARC-AGI-3 zeigt eine massive Lücke bei fluid-adaptiver Agentenintelligenz, Odysseys zeigt schwache Effizienz bei realistischen Web-Workflows, und das Agentic-Benchmark-Checklist-Paper zeigt, wie stark Benchmark-Design Ergebnisse verzerren kann.
- →METR: Measuring AI Ability to Complete Long Software Tasks (arXiv 2503.14499, v3)
- →METR: Time Horizon 1.1 Live-Dashboard / aktuelle Modellmessungen
- →METR: Time Horizon 1.1 Release Announcement (Jan 2026)
- →ARC Prize Foundation: ARC-AGI-3 (arXiv 2603.24621, Mär 2026)
- →Jang et al.: Odysseys - Realistic Long-Horizon Web Agents (arXiv 2604.24964, Apr 2026)
- →Zhu et al.: Rigorous Agentic Benchmarks / ABC (arXiv 2507.02825, v5)
- →Hendrycks et al.: A Definition of AGI (arXiv 2510.18212, v3)


